暇つぶし
日経255の構成銘柄一覧からインデックス, コード番号, 社名を抽出してCSV形式にする。
参照する表
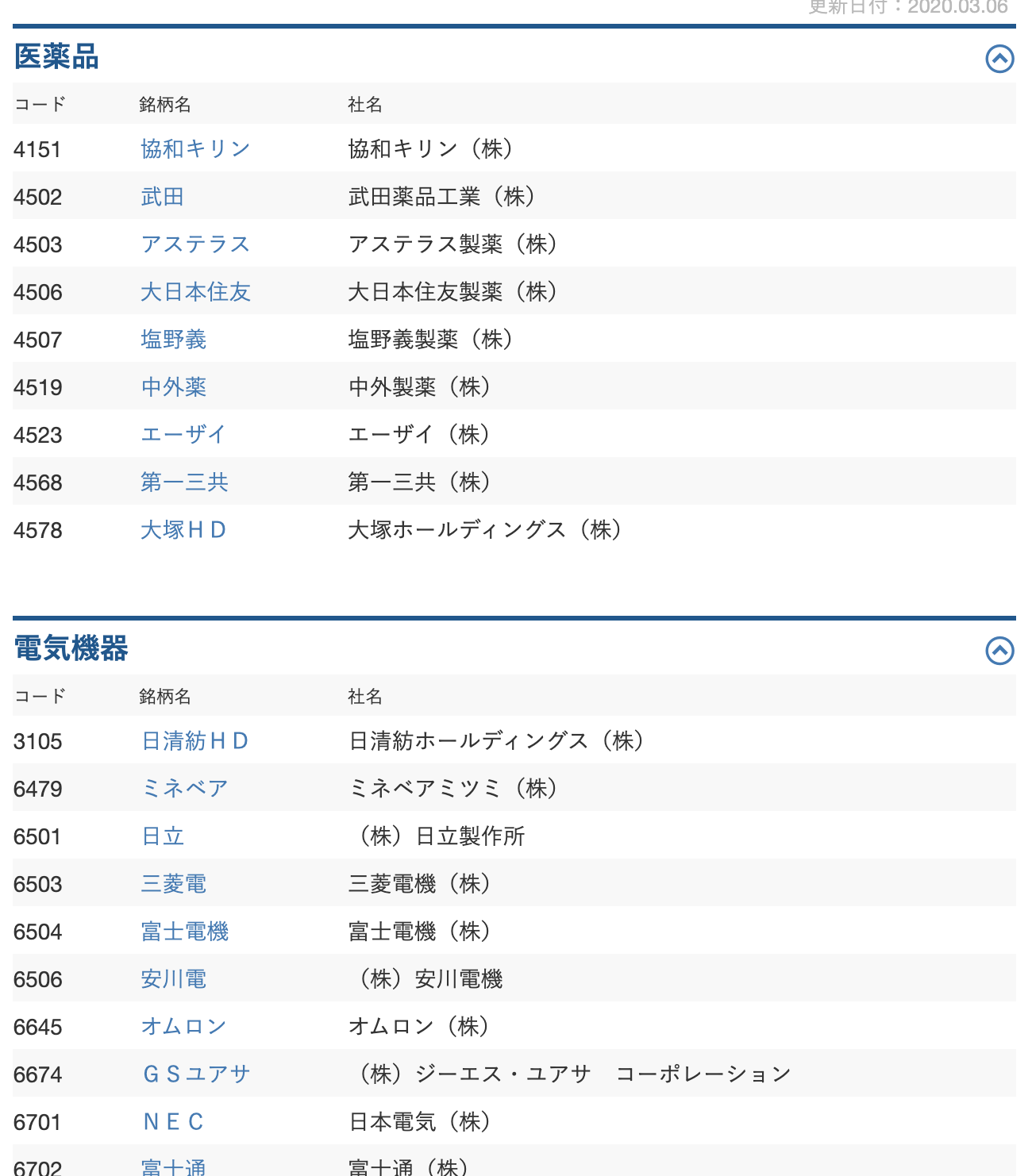
HTMLタグにtable要素は使われていない。
作成したコード
require 'open-uri' #URLにアクセスする為のライブラリを読み込みます。 require 'nokogiri' #Nokogiriライブラリを読み込みます。 require 'csv' #切り出すURLを指定します。 url = 'https://indexes.nikkei.co.jp/nkave/index/component?idx=nk225' charset = nil html = open(url) do |f| charset = f.charset #文字種別を取得します。 f.read end #htmlを解析し、オブジェクト化 page = Nokogiri::HTML.parse(html, nil, charset) nodes = page.xpath("//div[@class='row component-list']") array = [] nodes.each do |node| array << node.css('div').map(&:text) end outputs = [] outputs << ["No.", "コード", "会社名"] array.each_with_index{|element, index| data = [] data << (index + 1).to_s data << element[0] data << element[2] outputs << data } p outputs File.open("/Users/*****/*****/webscrape/nikkei255.csv", "w") do |f| #データをループ outputs.each { |line_array| p line_array #1行ごとに実行 line_array.each {|i| f.print(i) f.print(",") } #行末に改行コードを入力 f.print "\n" } end
結果

xpathの指定の仕方をミスしていて、データが121個しかなかった。指定をしっかりすれば、
もれなくデータを引っ張ってこれるかも。ただ、エクセルの方が格段に早く済みそう。w